





Pernah terfikir bagaimana carian enjin carian Google mengumpulkan dan mengatur data mereka dengan begitu cepat?

Enjin carian Google adalah alat yang hebat. Tanpa enjin carian seperti Google, mustahil untuk mencari maklumat yang anda perlukan semasa anda melayari Web. Seperti semua enjin carian, Google menggunakan algoritma khas untuk menghasilkan hasil carian.
Walaupun Google berkongsi fakta umum mengenai algoritma, butirannya adalah rahsia syarikat. Ini membantu Google untuk terus berdaya saing dengan enjin carian lain di Web dan mengurangkan peluang seseorang mengetahui cara menyalahgunakan sistem.
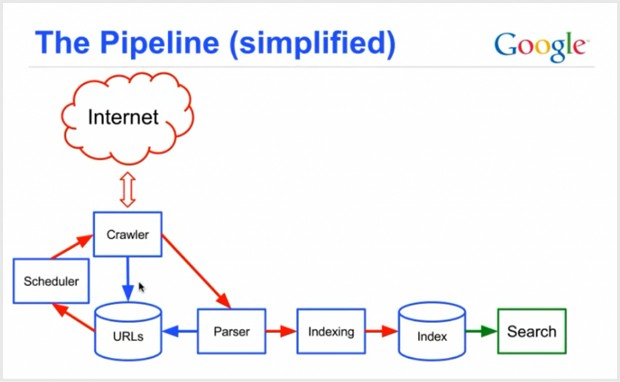
Google menggunakan program automatik yang disebut sebagai spider atau crawler, seperti kebanyakan enjin carian. Seperti enjin carian lain, Google mempunyai indeks kata kunci yang besar dan di mana kata-kata itu dapat dijumpai.
Apa yang membezakan Google adalah bagaimana ia menyusun hasil carian, yang seterusnya menentukan kaedah aturan Google memaparkan hasil di halaman hasil mesin pencari (SERP). Google menggunakan algoritma cap dagangan yang disebut PageRank, yang memberikan skor relevan pada setiap laman web.
Apakah itu SERP? – “Search Engine Results Page”
SERP adalah singkatan dari “Laman Hasil Enjin Carian”. Bagi sesiapa yang bekerja dalam pengoptimuman enjin carian atau PPC, laman web ini yang dapat dilihat sebagai harta yang bernilai – semakin tinggi kedudukan syarikat anda, semakin banyak pendedahan dan kredibiliti syarikat anda terhadap enjin carian.
PageRank? – Kedudukan Dalam Laman
PageRank adalah algoritma pertama yang digunakan oleh Google untuk menilai laman web. Ia menggunakan model melayari web yang sederhana untuk menganggarkan kebarangkalian melayari ke setiap laman web di internet. Ia menggunakan konsep jalan secara rawak dalam “Directed Acyclic Graph”. Model pelayaran web berfungsi seperti ini:
– 85% masa anda memilih pautan secara rawak di halaman yang anda kunjungi dan mengunjunginya (jika ada pautan)
– 15% masa anda memilih laman web rawak di internet dan pergi ke sana.
Enjin carian Google secara teknikalnya kompleks. Terdapat ribuan faktor berbeza yang diambil kira sehingga enjin carian dapat mengetahui apa yang harus pergi dan ke mana ianya patut pergi. Ia seperti kotak hitam yang sangat misteri, dan sangat sedikit orang yang mengetahui dengan tepat apa yang ada di dalamnya.
Bagaimana enjin carian merangkak web?
Tugas pertama Google adalah ‘merangkak’ (crawl) web dengan ‘labah-labah’ (spider). Ianya adalah program atau bot kecil automatik yang bergerak dalam internet untuk mencari semua maklumat baru.
Spider akan mencatat apa yang ada dalam laman web anda, dari tajuk yang anda gunakan hingga teks pada setiap halaman untuk mengetahui lebih lanjut mengenai siapa anda, apa yang anda lakukan, dan siapa yang mungkin berminat untuk mencari anda.
Oleh itu, cabaran besar pertama adalah mencari data baru, merekodkan apa yang ada, dan kemudian menyimpan maklumat tersebut (dengan beberapa ketepatan ) dalam pangkalan data.
Tugas Google seterusnya adalah untuk mengetahui cara terbaik memadankan dan memaparkan maklumat dalam pangkalan data ketika seseorang menaip pertanyaan carian. Penskalaan menjadi masalah lagi.
Langkah-langkah yang dijalankan oleh Enjin Carian:
– Merangkak Web
– Pengindeksan
– Algoritma
Web Crawling (nak sebut dalam bahasa melayu agak lucu, Merangkak Dalam Sesawang!)
Ini adalah kaedah di mana enjin carian dapat mengetahui apa yang diterbitkan di World Wide Web.
Pada dasarnya, semasa merangkak, ianya akan menyalin apa yang ada di laman web dan berulang kali memeriksa banyak halaman untuk melihat apakah halaman tersebut diubah dan membuat salinan dari sebarang perubahan yang dijumpai.
Program-program yang memiliki tugas ini disebut sebagai robot, crawler, labah-labah atau beberapa variasi menggunakan ‘web’. cth. web crawler (perangkak web)…
Pengindeksan
Setelah labah-labah merayap dalam halaman web, salinan yang dibuat dikembalikan ke enjin carian dan disimpan di pusat data. Pusat data sangat besar, koleksi pelayan yang dibuat khas yang berfungsi sebagai repositori semua salinan halaman web yang ada dibuat oleh perangkak.
Google memiliki berpuluh-puluh pusat data di seluruh dunia, yang dijaganya dengan sangat ketat dan merupakan antara bangunan berteknologi tinggi di dunia. Penyimpanan halaman web disebut sebagai ‘Indeks’, dan inilah simpanan data yang disusun dan digunakan untuk memberikan hasil carian yang anda lihat di menjin carian. Pengindeksan adalah proses mengatur banyak data dan halaman sehingga ianya dapat dicari dengan cepat untuk mendapatkan hasil yang relevan dengan pertanyaan carian anda.
Algoritma
Akhirnya, enjin carian mempunyai banyak koleksi salinan halaman web yang sentiasa dikemas kini dan disusun agar ianya dapat dengan cepat mencari apa yang anda ingin cari. Tetapi pada masa sama enjin carian memerlukan kaedah di mana ianya dapat diberi peringkat (ranking atau kedudukan) mengikut kesesuaian dengan istilah carian anda – di sinilah Algoritma dimainkan.
Algoritma adalah persamaan yang sangat kompleks dan panjang yang menghitung nilai untuk mana-mana laman web yang berkaitan dengan istilah carian. Tidak ramai antara kita yang tidak tahu apa sebenarnya algoritma itu, kerana enjin carian cenderung menyimpan rahsia ini dari pesaing dan orang yang ingin cuba mengeskploitasi enjin carian untuk sampai ke tempat (kedudukan) teratas.
Walaupun begitu, cukup banyak algoritma yang telah dibuat untuk membolehkan SEO (Search engine Optimization) menasihati pemilik laman web tentang cara meningkatkan laman web mereka dan faktor SEO untuk naik dalam kedudukan.
Statistik mengatakan bahawa Google kini memproses lebih dari 40,000 pertanyaan carian setiap saat secara purata (gambarkan di sini), yang diterjemahkan menjadi lebih dari 3,5 bilion carian setiap hari dan 1.2 trilion carian setiap tahun di seluruh dunia.


Perhatian sebentar…
—
Sejak 2012, kami bersungguh menyediakan bacaan digital secara percuma di laman ini dan akan terus mengadakannya selaras dengan misi kami memandaikan anak bangsa.
Namun menyediakan bacaan secara percuma memerlukan perbelanjaan tinggi yang berterusan dan kami sangat mengalu-alukan anda untuk terus menyokong perjuangan kami.
Tidak seperti yang lain, The Patriots tidak dimiliki oleh jutawan mahupun politikus, maka kandungan yang dihasilkan sentiasa bebas dari pengaruh politik dan komersial. Ini mendorong kami untuk terus mencari kebenaran tanpa rasa takut supaya nikmat ilmu dapat dikongsi bersama.
Kini, kami amat memerlukan sokongan anda walaupun kami faham tidak semua orang mampu untuk membayar kandungan. Tetapi dengan sokongan anda, sedikit sebanyak dapat membantu perbelanjaan kami dalam meluaskan lagi bacaan percuma yang bermanfaat untuk tahun 2024 ini dan seterusnya. Meskipun anda mungkin tidak mampu, kami tetap mengalu-alukan anda sebagai pembaca.
Sokong The Patriots dari serendah RM2.00, dan ia hanya mengambil masa seminit sahaja. Jika anda berkemampuan lebih, mohon pertimbangkan untuk menyokong kami dengan jumlah yang disediakan. Terima kasih. Moving forward as one.
Pilih jumlah sumbangan yang ingin diberikan di bawah.
RM2 / RM5 / RM10 / RM50
—
Terima kasih

